在线 sql 学习网站
数据结构和算法(一)概述
数据结构,用来描述数据间的关系
算法,指解决某一特定问题的步骤
数据结构为算法服务,算法是特定问题下的解决办法,故没有通用性算法,应具体问题具体分析
一、数据结构
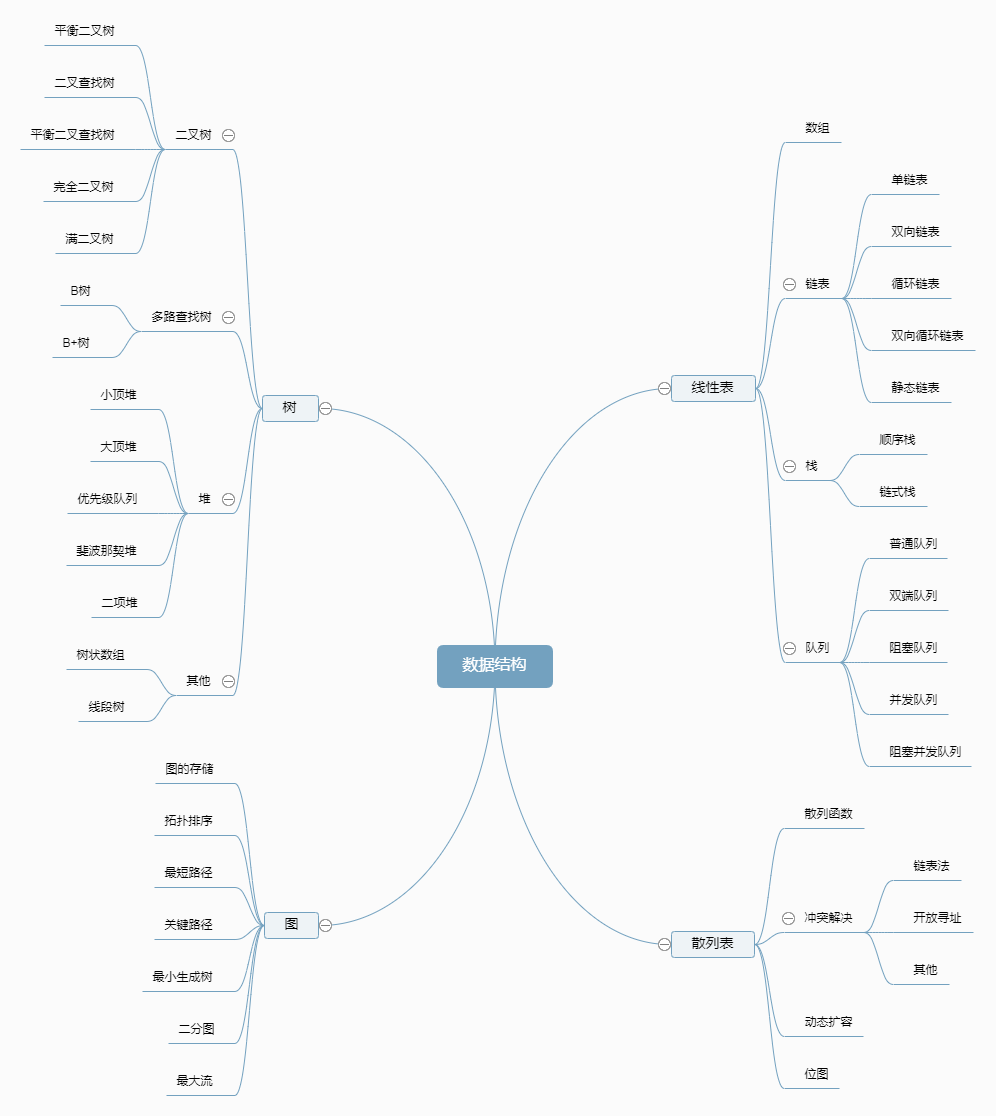
以上为数据结构的逻辑结构,在计算机内部的物理存储结构有:顺序结构,链式结构、索引结构和散列结构。
二、算法
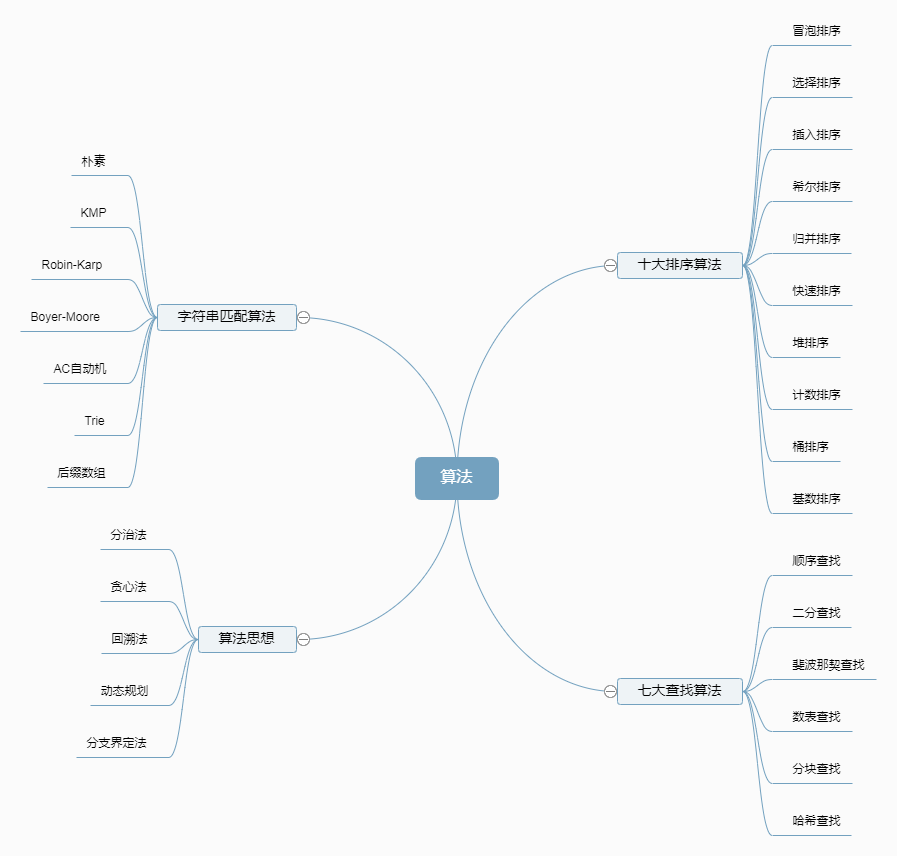
三、学习目标
数据结构,熟悉各数据结构特点,掌握增删改查的操作方法。
算法学习,理解各算法所解决问题的定义,掌握算法复杂度分析方法,体会各算法的基本思想
四、学习途径
在线课程
斯坦福大学算法,https://www.coursera.org/specializations/algorithms#courses可视化平台
https://algorithm-visualizer.org/,特点:对算法有分类
https://visualgo.net/zh,特点:有中文,有练习题目
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html,特点:可以输入可操作在线练题
leetcode: https://leetcode.com/
hihocoder: http://hihocoder.com/hiho
lintcode: https://www.lintcode.com/
https://pintia.cn/problem-sets?tab=0
引用列表:
算法思想总结:
https://zhuanlan.zhihu.com/p/36903717
https://blog.csdn.net/m0_37872090/article/details/80819788
排序算法:
http://ddrv.cn/docs/SortingAlgorithm/
查找算法:
https://blog.csdn.net/weixin_39241397/article/details/79344179
数据结构和算法概述
https://zhuanlan.zhihu.com/p/93928797
cpp标准库
强制类型转换
标准库提供了常见数据结构和常用算法
static_cast:基本类型之间,基类指针和子类指针(向下转换没有 dynamic_cast 安全)
reinterpret_cast:指针类型之间,整数和指针类型之间
dynamic_cast:类指针或引用的相互转换,需要虚函数表支持,有运行时类型检查,所以可以在类层次中向上和向下安全转换
const_cast:去除常量指针或引用的 const 属性
智能指针
智能指针是类,利用栈退出时临时变量自动销毁的原理,在析构函数中释放资源,避免内存泄漏
- unique_ptr:没有复制和赋值构造函数,同一时间只有一个智能指针指向对象
- shared_ptr:采用引用计数,当计数为 0,销毁
- weak_ptr:解决 shared_ptr 循环引用导致资源泄漏,weak_ptr 由 shared_ptr 创建,但是不影响引用计数
- auto_ptr(C++17 中移除)
数据结构和算法
array:固定大小的数组,底层是数组
vector:可以改变大小的数组,底层是数组
deque:
算法:
c语言标准库
类型相关
- 基本类型:char、short、int、long
数值极限头文件<limits.h>和<float.h>
- CHAR_MIN、CHAR_MAX:char 类型极限
- INT_MIN、INT_MAX:int 类型极限
- FLT_MIN、FLT_MAX:float 类型极限
- 附加基本类型:size_t、ptrdiff_t、NULL 等,定义于<stddef.h>
极限头文件:<stdint.h>
- SIZE_MAX:size_t 类型对象的最大值
- 定宽整数类型:定义于头文件<stdint.h>
- int8_t:8 位有符号整数类型
- uint8_t:8 位无符号整数类型
- INT8_MIN:int8_t 类型最小值
- INT8_MAX:int8_t 类型最大值
内存管理
1 | void* malloc( size_t size ); |
字符串库
可参考我的文章:字符集和编码
宽字符串:每个字符的字节数固定的,通常是 Unicode 编码,也就是 Unicode 字节集中的序号
窄字符串:也叫多字节字符串,每个字符占用的字节个数不同,比如 UTF-8、GB2312、GBK 等;
宽字符和窄字符相互转换:
由于宽字符串是 Unicode 编码,所以跟环境无关
窄字符串的编码是可变的,比如 UTF-8、GB2312、GBK 等
所以窄字符串和宽字符串在转换过程中,会根据当前活动的 locale 的字符编码来识别窄字符串,然后进行转换
C 语言字符串操作函数分为 3 类:单字节字符串、多字节字符串和宽字符串
输入输出库
将字符串打印到控制台时,字符串的编码格式需要跟终端的一致
c_cpp 概述
c/c++的学习分为两个部分
一、语言标准
语言标准定义了功能特性和标准库两部分。
功能特性由编译器负责具体实现,比如 linux 下 gcc,windows 下 Visual Studio
标准库实现依赖于具体平台,比如 linux 下 c 标准库是 glibc,windows 下的 MSVCRT.DLL。
c/c++是有国际标准化组织 ISO 制定标准,网址为:https://www.iso.org
c11 标准参考:https://www.iso.org/standard/57853.html
c++2017 参考:https://www.iso.org/standard/68564.html
以上是需要收费才能下载,我的百度网盘中可下载:https://pan.baidu.com/s/1Dc6lyRPryC9ShbPsZ1U5uQ,提取码:c8kw
其他可以免费查看的网站:
各种语言或软件 API 文档:https://tool.oschina.net/apidocs
c/c++语言参考:https://zh.cppreference.com
除了参考语言标准,也可对照具体实现进行学习
glibc 官方文档:https://www.gnu.org/software/libc/manual/html_node/index.html
二、运行环境
c/c++程序生成的可执行程序,由操作系统加载运行。因此这部分的学习主要学会使用操作系统相关 API,比如文件操作,进程线程相关,网络通信等。
应用程序可通过系统调用与操作系统进行交互。系统调用需要操作寄存器等,所以 glibc 封装了这部分操作,提供了简单的 c 语言接口
linux 下系统调用在内核代码中 sys_call_table 定义。
windows 下有 kernel32.dll、user32.dll、gdi32.dll 实现了系统 API。
总结:
学习 c/c++除了学习基本语法,标准库和系统 API 的学习将是重点。
linux 系统调用列表官方列表:http://man7.org/linux/man-pages/dir_section_2.html
https://www.ibm.com/developerworks/cn/linux/kernel/syscall/part1/appendix.html
编程语言的思考
工作几年,先后接触 c/c++,python,lua,dart,JavaScript,java 各种语言,记录下对于一个编程语言的理解,对一个编程语言的理解,应该关注两个方面
一、语言特性
语言特性由编译器具体实现,具体包括:
强类型 vs 弱类型
强类型就是类型很硬,不太接受转换
比如 c++就是强类型,不同类型转换需要各种 cast
JavaScript 就是弱类型,一个变量,一会数字,一会字符串,一会对象都没问题静态类型 vs 动态类型
静态类型:程序运行前确定变量类型,需事先声明或者由编译器推导
动态类型,程序运行时才进行类型绑定和检查静态语言 vs 动态语言
程序在运行时可以更改代码结构,比如 JavaScript 随时给一个对象添加成员或者添加函数值类型 vs 引用数据类型
JavaScript 中除了基本数据类型外,其他都是引用类型,所以变量赋值后其实指向的是同一对象
总结:
变量声明时是否需要指定类型->静态类型 vs 动态类型
声明后的类型能否相互转换->强类型 vs 弱类型
程序运行时,能否改变对象内部结构->动态语言 vs 静态语言
但,对于 dart 语言,所有这些都不算数,
既可以编译成二进制,AOT,又可以解释运行
变量声明既可以指定类型,也可以 dynamic 声明不指定类型
不支持反射,所以是静态语言
类型不可随意转换,是强类型语言
二、运行环境
运行环境就是 runtime,包括虚拟机或者真实的操作系统,需要注意的有
编译运行 vs 解释执行
编译型:源代码->编译器->可执行代码
解释型:解释器读取源代码,编译,然后运行。
区别仅仅是源代码翻译成目标代码的时机不同。
c/c++是编译型,各源文件编译成 obj,后经过连接器链接为可执行文件,后操作系统加载执行
js,python 是解释型,先编译为字节码,后由虚拟机加载执行。
要注意编译单位:c/c++是以文件为单位,nodejs 和 python 同样,但网页中 js 是以代码块独立翻译,执行,但各代码块共享变量异步编程模型
nodejs 是单线程异步模型,异步模型导致回调地狱问题,后出现 await,async,以同步编程方式来编写异步代码。更好维护垃圾回收
只管使用,不用操心内存释放。
越高级语言,开发者越不需要关心底层,c/c++,不需要关心汇编指令,但是需要负责内存的申请和释放,而 java,js,dart 等现代化语言,开发者不需要关心内存问题,这是语言发展的必然。
个人理解,欢迎留言讨论