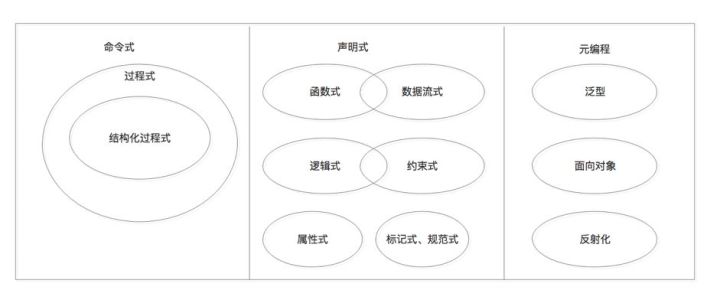
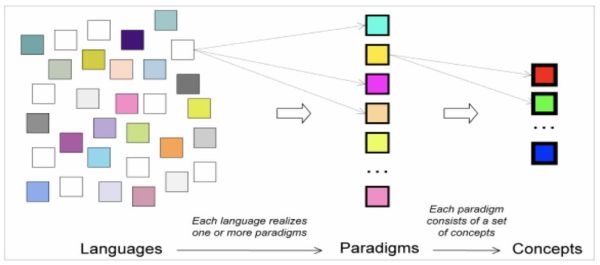
阅读本文之前,可先参考c 语言核心
c++相对于 c 语言,主要是增加了面向对象和模板编程
c++中的实体 C++ 程序中的实体包括:值、对象、引用、 结构化绑定 (C++17 起)、函数、枚举项、类型、类成员、模板、模板特化、命名空间和形参包。预处理器宏不是 C++ 实体。
对象类型:非函数类型、非引用类型且非 void 类型的
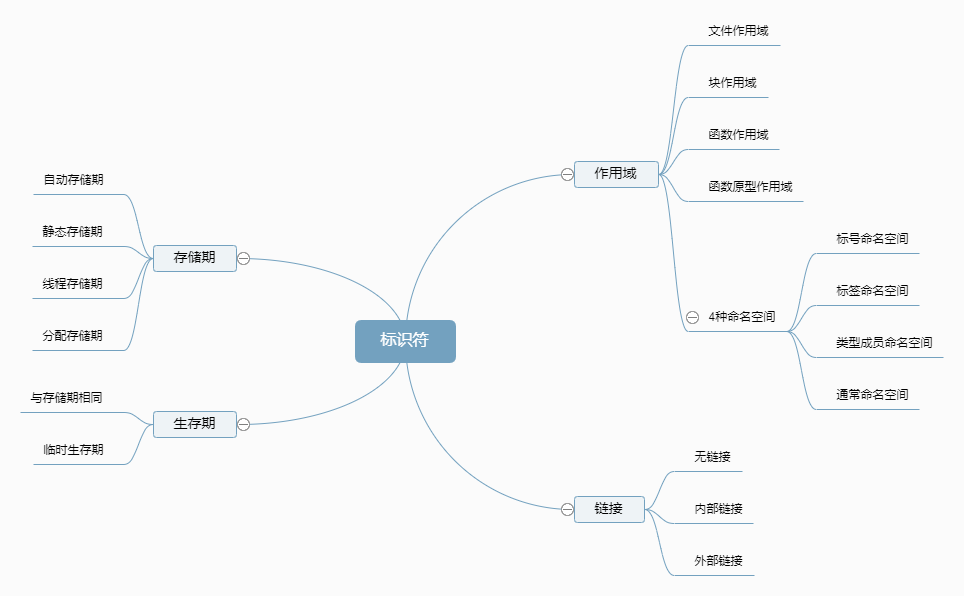
名字查找和命名空间 作用域:文件作用域(全局作用域)、命名空间作用域、类作用域、块作用域、枚举作用域、函数作用域、函数形参作用域、模板形参作用域
内部链接和外部链接 内部链接:其他编译单元无法访问的名称,拥有内部链接,相反是外部链接
以下为内部链接:
所有声明
类型(struct/union/enum 等)
命名空间中的 static 函数和变量以及 const 常量
inline 函数
以下为外部链接:
命名空间中的非 static 函数和变量
类成员函数(包含成员函数和 static 成员函数)和静态成员变量
类型比较 c++有如下类型:
基本类型
void
nullptr:空指针
算术类型
整数类型
bool 类型
字符类型
窄字符:(char、signed char、unsigned char、char8_t)
宽字符:(char16_t、char32_t、wchar_t)
整数类型:各种限定的 int
浮点类型:(float 、 double 、 long double)
复合类型
数组类型
函数类型
指针类型(包括对象指针,函数指针,成员函数指针,数据成员指针)
引用类型
枚举类型
类类型
联合体类型
基本类型异同 空指针字面量
为什么需要空指针字面量?
c 语言空指针定义于<stddef.h>,它可以被定义为 ((void*)0), 0 或 0L,这取决于编译器供应商。
1 2 3 4 5 6 7 #define NULL 0 #define NULL ((void*)0) int * p = malloc (10 * sizeof (int )); void *pv = p;
c++中空指针定义如下:
1 2 3 #define NULL 0 #define NULL nullptr
问题一:为什么 c++把 NULL 定义为 0,而不是 void? )到其他类型指针的隐式类型转换
1 2 3 4 #define NULL ((void*)0) int * a = NULL ; int * a = (int *)NULL ; int * a = 0 ;
结论:c++中,NULL 只能被定义为 0
问题二:有了 NULL 表示空指针,c++11 为什么增加 nullptr_t ?
1 2 3 4 5 6 7 8 void Func (char *) void Func (int ) int main () Func(NULL ); Func(nullptr ); }
c++11 的解决方案,定义个 std::nullptr_t 类型,该类型定义了转到任意指针类型的转换操作符,同时不允许该类型的对象转换到非指针类型
结论:用 nullptr 类型表示无效指针后,既不需要初始化时显示转换的麻烦,又避免 NULL 定义为 0 时的函数重载问题,而保留 NULL 只是为了向后兼容。所以 c 中使用 NULL,c++11 中使用 nullptr。
bool 类型
1 2 3 #define bool _Bool #define true 1 #define false 0
c99 后,bool,true,false 为宏定义,在<stdbool.h>中
字符类型
c++中,目前有以下内置字符类型(关键字):
c 语言中,使用宏定义实现:
1 2 3 typedef unsigned short wchar_t ; typedef uint_least16_t char16_t ; typedef uint_least32_t char32_t ;
字符串使用原则:
引用类型
面向对象 通过 class 或者 struct 支持面向对象编程
编译器默认会定义的成员函数:
1 2 3 4 5 6 7 8 class A { A() {} A( const A & ) {} }
c++中的多态:
模板编程 通过模板编程支持范型编程,让程序员编写与类型无关的通用代码,比如通用算法
1 2 3 4 5 6 template <class 形参名, class 形参名, ...> 返回类型 函数名(参数列表) {template <class 形参名, class 形参名, ...> class 类名{}
模板有显式实例化,隐式实例化,特化(具体化)